Microsoft and Python Machine Learning, a modern love story, part 2/2
In part 1 we created a workflow centered around a VSCode devcontainer and the AzureML Python SDK. We finished with running a Python script on our AzureML remote compute target with minimal fuss. This also meant that most of the configuration of the compute target was by default and out of our hands. In this blog we will dive into the AzureML Compute Target Environment; configuring it to support a GPU workload using PyTorch. We end with a proposal to unify local development and remote environments for AzureML.
1 Compute Target Environment
1.1 Docker image management
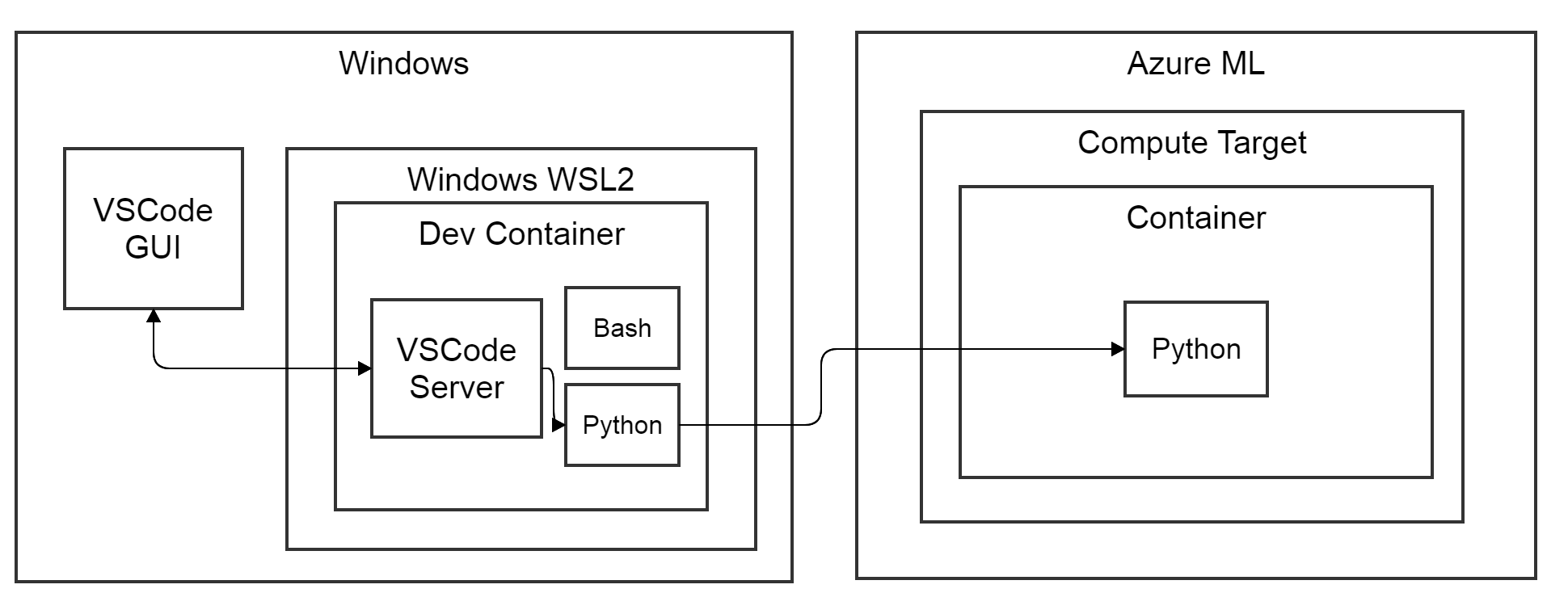
In the diagram below we see the Python workload running within a remote docker container on the compute target. If we create a CPU cluster and we do not specify anything besides a RunConfiguration pointing to compute target (see part 1), then AzureML will pick a CPU base docker image on the first run (https://github.com/Azure/AzureML-Containers). On top of the base image a conda environment is created and default python dependencies are installed to create an AzureML-SDK enabled Python runtime. After building the image it is pushed to the docker repository linked to your AzureML workspace with a random UUID in its name (pattern: azureml/azureml_<UUID>). During a run of your code the compute instance will pull the custom image. If the environment configuration changes a rebuild is triggered at the start of the run. Note that these images are not garbage collected and your costs increase as you store more images.
1.2 Environment class
The Environment class is a composition of various classes that configure environmental variables, programming languages, computing frameworks and Docker. The Environment consists of sections for Docker, Python, R and Spark. For instance, the PythonSection exposes multiple methods to create a Python environment from an existing conda environment, a conda specification file, pip requirements file or programmatically added dependencies. The AzureML environments can be registered to the workspace for later use. The goal is to make reusable environments for training and deploying with AzureML (docs.microsoft/how-to-use-environments). In our DIY MLOps this would be analogues to zipping your entire conda virtualenv and uploading it to an artifactory for later deployment. The detail of the MLOps API in the Python SDK is impressive and their recent shift to the environment driven configuration provides transparency and flexibility for the user.
We will focus on the Docker and Python sections.
- DockerSection, configures the runtime docker image, container build and run parameters
- base_image, full docker image name with tags to use to build the runtime environment
- base_image_registry, ContainerRegistry where the base image resides. Defaults to the MCR (Microsoft Container Registry)
- enabled, Boolean to enable docker, which seems to be ignored in remote compute_targets and is forced to True
- gpu_support, This boolean property is deprecated, as it is now autodetected. We will mention more about this later.
- arguments, extra arguments for the Docker run command. Happy to see such power in the hands of the AzurML user
- PythonSection, configures the runtime Python interpreter and its dependencies
- conda_dependencies, pip and conda dependencies added programmatically
- conda_dependencies_file, pip and conda dependencies from an existing file.
- interpreter_path, path to the Python interpreter, if you want to use your own pre-existing Python interpreter
2 Training PyTorch on a GPU with AzureML
To use Deep Learning for text classification we wanted to train the latest RoBERTa PyTorch incarnation on a GPU powered compute target. AzureML provides a range of VMs with GPU support (VM-sizes-gpu). A starter size is the “NC6_standard” which has access to one-half of a k80 card which counts for 1 GPU (nc-series). Selecting this size for our AMLCompute class enables the GPU support by running our containers with “nvidea_docker” instead of the standard docker engine. This auto-detection is fairly new and I found it to be bugged for single compute instances (msdn-post). For compute clusters the GPU auto-detection works fine and thus the “gpu_support” Boolean on the Environment.DockerSection is deprecated (azureml.core.environment.dockersection).
We will create a runtime environment ready to do GPU support. We refer to part 1 for the creation of a computing cluster, which is also the preferred way of working with only one VM. The only change from part 1 is that we change the VM size to a GPU ready one such as the “NC6_standard”.
2.1 Creating a runtime PyTorch environment with GPU support
For our purposes we are running on Python 3.6 with Pytorch >=1.4.0 and cuda 10.1. As our base image we take an official AzureML image, based on Ubuntu 18.04 (AzureML-Containers/base/gpu) containing native GPU libraries and other frameworks. For instance, AzureML allows distributed training of deep learning models through the Horovod framework (https://github.com/horovod/horovod), which has OpenMPI as communication protocol between VM nodes. On AMLCompute clusters we do need to set docker.enabled on our Environment, as it is forced to True. Additionally, the use of nvidea_docker over the standard docker engine is auto-detected, thus setting gpu.support on the Environment is also redundant.
To manage the Python packages in our remote Conda environment we manipulate a CondaDependencies object and attach it to our Environment object. We call “add_conda_package” on this object with a package name and optional version and build. In the case of PyTorch we needed a specific build to enable the GPU backend. We also needed to add the “pytorch” conda channel with “add_channel” to install these packages. I liked the programmatic approach of dependency management in this instance, although you might prefer using a conda or pip requirements file.

2.2 Using an environment for an Estimator
2.2.1 Estimator class
For training our PyTorch model we use the Estimator class (azureml.train.estimator.estimator). The estimator can be submitted to an AzureML experiment, which runs it on a compute target. Note that preconfigured estimators for PyTorch, Tensorflow and SKLearn are deprecated as of 2019-2020. These were too implicit about configuring the runtime environment, which made them inflexible, hard to maintain and magic to the user. All new users are advised to use the vanilla Estimator class in combination with the Environment class.
The Estimator class has many deprecated arguments for creating an estimator object. It supports both the deprecated implicit API and the new Environment based configuration. Therefore, we need to ignore almost all the parameters when creating an estimator object and focus only on the following.
- environment_configuration, is where we pass in the Environment object with our runtime configuration (see section 1.2)
- compute_target, a reference to our compute target, in our case an AMLCompute object for a remote compute cluster
- source_directory, determines which part of your local filesystem is uploaded to the remote compute target. If you use Python modules stored locally they will need to be included to import them in your script.
- entry_script, a relative path to your script from within the “source_directory”.
- script_params, command line arguments passed to our “entry_script” during runtime. A dictonary such as {“--epochs”, 10}
2.2.2 Submitting an estimator to an experiment
To run our estimator within our environment we need to submit it to an experiment. The experiment registers all the runs within the AzureML backend and collects logging and output. With the AzureML-SDK we are also able to register our models and datasets (not shown). Below we create and estimator object and pass it our environment object defined in settings.py. The compute target is retrieved with the functionality shown in part 1. We create an experiment or retrieve an existing experiment under the name “test-estimator” and submit our estimator to it for a run.

3 Unifying local development and remote training
Looking at the diagram at the top of this blog we see Docker containers running both locally and remotely. Both run parts of our Python code. Locally we run the code that launches our AzureML experiment and estimator. Remotely we run our model training code to train our model. One of the promises of Docker is to unify the runtime environment between development and production. Along those lines we want to debug our training code locally against the environment it encounters remotely. In other words, we want to use the same Docker image for local development and remote training of our model. We can locally pull the Docker image that AzureML builds and pushes to our workspace, by authenticating our local docker with our AzureML Docker registry (container-registry-authentication). This authenticating and pulling can be simplified by the docker and azure account extensions for VSCode. We take the pulled Docker image as a basis for a VSCode devcontainer (see also part 1) within which we edit and run our code locally. Note, we will pass over the details of local GPU support and assume that the ML library falls back on GPU compute for local testing.
3.1 Creating a devcontainer from an AzureML compute target image
A VSCode devcontainer requires two files; a Dockerfile and a devcontainer.json inside a “.devcontainer/” folder within our project. The Dockerfile describes our Docker image from which we construct a container. The devcontainer.json file is specific to VSCode and configures the integration with the Docker container, such as the Python interpreter path, linting executable paths, VSCode extensions and bind mounts.
3.1.1 Dockerfile deriving from an AzureML image
Within our Dockerfile (see below) we inherit from the base image in our AzureML ContainerRepository. Locally we want to install Python dev dependencies such as black, pylint and pytest in the container. We install them inside the same Python environment that AzureML uses to run our code, although other choices can be made. AzureML generated Conda environments are located in “/azureml-envs/” on the image. The name of the Conda env contains another random UUID with pattern: “azureml_<UUID>”. In our Dockerfile we use pip associated with this env to install our Python dev dependencies and we use apt-get to install vim and git, while making sure to clean up after these operations.

3.1.2 Integrating VSCode with the container
The devcontainer.json file defines our integration between VSCode and our Docker container. We define a name for our devcontainer followed with the path to our Dockerfile (You can also set an image directly). Followed by the VSCode settings with paths for our Python interpreter and various devtools such as black, pytest and pylint. We finish up with the VSCode extensions we want to install within our devcontainer.

3.2 Summary: AzureML image devcontainer
With the AzureML Environment class we defined the runtime configuration of the remote compute target based on a GPU enabled docker image. This environment was consolidated by AzureML as a custom docker image it pushed to its docker registry. We used this custom image to create a VSCode devcontainer to unify our development and remote environment. This allows us to test locally against the same environment we are running on remotely. In part 1 we were different containers locally and remotely (part 1).
4 AzureML a unified workflow
In this two-part blog we looked at a workflow for AzureML using VSCode devcontainers. We focused on Windows as an OS, but the workflow works as well for Linux as long as your distribution is supported by the AzureML-SDK (specifically its data-prep dependency: data-prep-prerequisites). We have made our way to a unified environment configuration of our local development and remote compute target. Thank you for your attention and I look forward to blogging about more topics related to Python, Machine Learning and Data engineering.
4.2 Potential breaking points for automating this workflow
The two random UUIDs that are generated by AzureML when creating the Conda env on top of the base image and in the name of the Docker repository are potential breaking points for automating this workflow across teams and experiments. The name of the Docker repository generated by AzureML can be found in the “20_image_build_log.txt” log file of the experiment run in the AzureML studio (https://ml.azure.com), in the interface of the docker registry associated with the AzureML workspace on portal.azure.com or by using the its API. A list of Conda environments on the image can be obtained by running the following command.