MLOps: a tale of two Azure pipelines
Goal
MLOps seeks to deliver fresh and reliable AI products through continuous integration, continuous training and continuous delivery of machine learning systems. When new data becomes available, we update the AI model and deploy it (if improved) automatically with DevOps practices. Azure DevOps pipelines support such practices and is our platform of choice. AI or Machine Learning is however focused around AzureML, which has its own pipeline and artifact system. Our goal is to combine DevOps pipelines with AzureML pipelines in an end-to-end MLOps solution. We want to continuously train models and conditionally deploy them on our infrastructure and applications. More specifically, our goal is to continuously update a PyTorch model running in an Azure function.
Solution overview
The following diagram shows our target solution. Three triggers are shown at the top. Changes to the infrastructure-as-code triggers the Terraform infrastructure pipeline. Changes to the Python code of the function triggers the Azure function deploy pipeline. Finally, new data on a schedule triggers the model training pipeline, which does a conditional deploy of the function with the new model if the new model is better.

1 DevOps infrastructure pipeline
Within a DevOps pipeline we can organize almost any aspect of the Azure cloud. They allow repeatable and reproducible infrastructure and application deployment. Some of the key features are:
- Support to automate almost all Azure Services
- Excellent secret management
- Integration with Azure DevOps for team collaboration and planning
1.1 Pipeline jobs, steps and tasks
DevOps pipelines are written in YAML and have several possible levels of organization: stages, jobs, steps. Stages consist of multiple jobs and jobs consist of multiple steps. Here we focus on jobs and steps. Each job can include a condition for execution and each of its steps contains a task specific to a certain framework or service. For instance, a Terraform task to deploy infrastructure or an Azure KeyVault task to manage secrets. Most tasks need a service connection linked to our Azure subscription to be allowed to access and alter our resources. In our case, we appropriate the authentication done by the Azure CLI task to run Python scripts with the right credentials to interact with our AzureML workspace.
1.2 Infrastructure as code
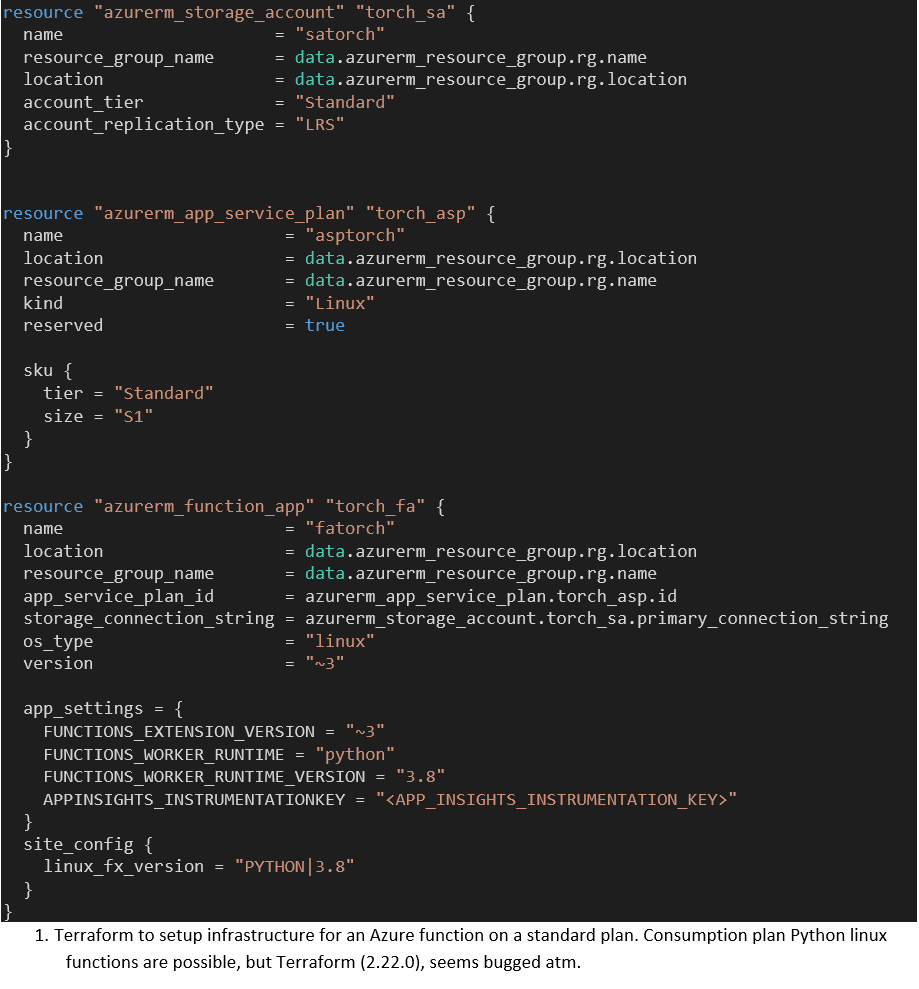
There are good arguments to use tools such as Terraform and Azure Resource Manager to manage our infrastructure, which we will try not to repeat here. Important for us, these tools can be launched repeatedly from our DevOps pipeline and always lead to the same resulting infrastructure (Idempotence). So, we can launch the infrastructure pipeline often not only when there are changes to the infrastructure-as-code. We use Terraform to manage our infrastructure, which requires the appropriate service connection.
The following Terraform definition (Code 1) will create a function app service with its storage account and Standard app service plan. We have included it as the documentation Linux example did not work for us. For full serverless benefits we were able to deploy on a consumption plan (elastic), but the azurerm provider for Terraform seems to have an interfering bug that prevented us from including it here. For brevity, we did not include the DevOps pipelines steps for applying Terraform and refer to the documentation.
2 AzureML pipeline
AzureML is one of the ways to do data science on Azure, besides Databricks and the legacy HDInsight cluster. We use the Python SDK for AzureML to create and run our pipelines. Setting up an AzureML development environment and running of training code on AMLCompute targets I explain here. In part 2 of that blog I describe the AzureML Environment and Estimator, which we use in the following sections. The AzureML pipeline combines preprocessing with estimators and connects them with PipelineData objects.
Some benefits are:
- Reproducible AI
- Reuse data pre-processing steps
- Manage data dependencies between steps
- Register AI artifacts: model and data versions
2.1 Pipeline creation and steps
Our Estimator wraps a PyTorch training script and passes command line arguments to it. We add an Estimator to the pipeline by wrapping it with the EstimatorStep class (Code 2). To create an AzureML pipeline we need to pass in the Experiment context and a list of steps to run in sequence (Code 3). The goal of our current Estimator is to register an updated model with the AzureML workspace.


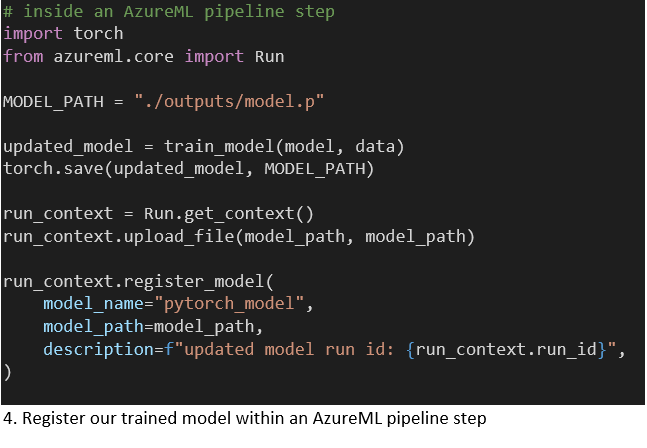
2.2 Model artifacts
PyTorch (and other) models can be serialized and registered with the AzureML workspace with the Model class. Registering a model uploads it to centralized blob storage and allows it to be published wrapped in a Docker container to Azure Docker instances and Azure Kubernetes Service. We wanted to keep it simple and treat the AzureML model registration as an artifact storage. Our estimator step loads an existing PyTorch model and trains it on the newly available data. This updated model is registered under the same name every time the pipeline runs (code 4). The model version is auto incremented. When we retrieve our model without specifying a version it will grab the latest version.
3 Combining AzureML and DevOps pipelines
3.1 DevOps pipeline centric architecture
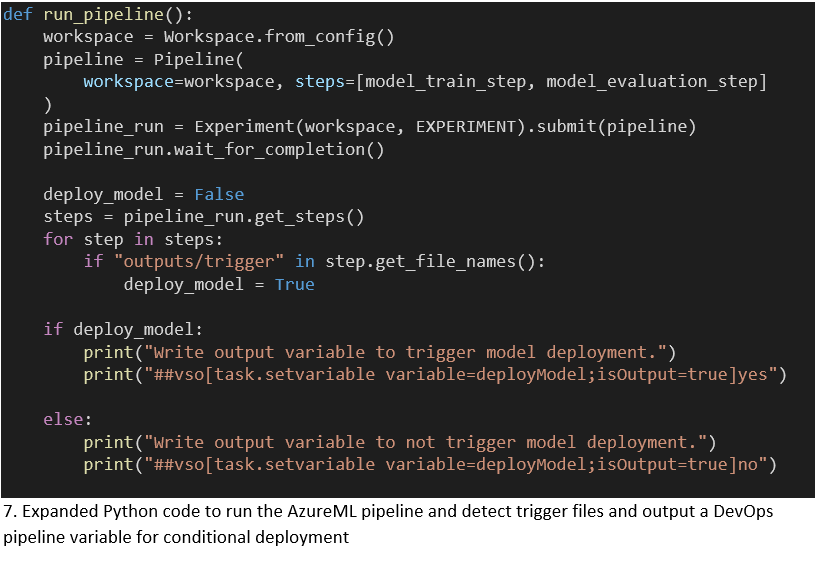
In our approach to MLOps / Continuous AI the DevOps pipeline is leading. It has better secrets management and broader capabilities than the AzureML pipeline. When new data is available the DevOps pipeline starts the AzureML pipeline and waits for it to finish with a conditional decision whether to deploy the model. This decision is based on the performance of the model compared to the previous best model. We schedule the model pipeline at regular intervals when new data is expected using the cron trigger.

3.2 Launching AzureML from DevOps
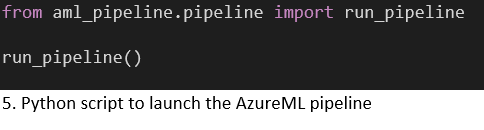
An Azure CLI task authenticates the task with our service connection, which has access to our AzureML Workspace. This access is used by the Python script to create the Workspace and Experiment context to allow us to run the Pipeline using the AzureML SDK. We wait for the AzureML pipeline to complete, with a configurable timeout. This timeout is limited by Azure DevOps to 2 hours. The implications of this are discussed at the end of the blog.
A basic Python script is shown (Code 5) that kicks of the AzureML pipeline in Code 3. This script is launched from an AzureCLI task (Code 6) for the required authentication. Note: It is not ideal that we need an account with rights on the Azure subscription level to interact with AzureML even for the most basic operations, such as downloading a model.

3.3 Conditional model deployment in DevOps
An updated model trained with the latest data will not perform better by definition. We want to decide whether to deploy the latest model based on its performance. Thus, we want to communicate our intent to deploy the model from AzureML to the DevOps pipeline. To output a variable to the DevOps context we need to write a specific string to the stdout of our Python script.
In our implementation each step in the AzureML pipeline can trigger a deployment by creating the following local empty file “outputs/trigger”. The “outputs” directory is special and Azure uploads automatically to the central blob storage accessible through the PipelineRun object and the ML studio. After the AzureML pipeline is completed we inspect all the steps in the PipelineRun to see whether a trigger file was created. Followed by writing a variable to the DevOps context as a Task output variable.
4 Deploy model and code to an Azure function
4.1 Conditional DevOps deploy job
We have trained a new model and want to deploy it. We need a DevOps job to take care of the deployment, which runs conditionally on the output of our AzureML training pipeline. We can access the output variable described above and perform an equality check within the jobs’ condition clause. Code 8 below shows how we access the task output variable from the previous train job in the condition of the deploy job.

4.2 Retrieve the latest model version
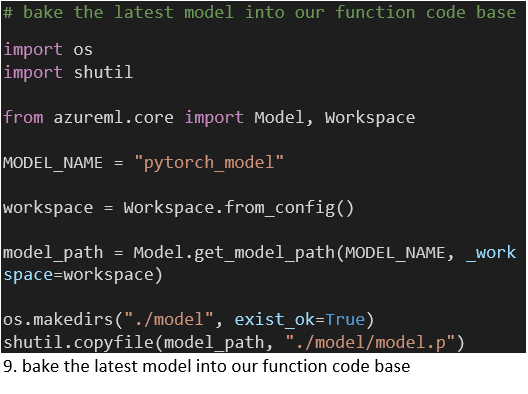
To retrieve the latest model from the AzureML Workspace we use an Azure CLI task to handle the required authentication. Within it we run a Python script, which attaches to our Workspace and downloads the model to a directory within the directory that holds our function code (Code 9). When we deploy our function this script is called to package our model with our Python code and requirements (Code 10, task 3). Each model release thus implies a function deploy.
4.3 Deploy model and code to our function app
The azure-functions-core-tools support local development and deployment to a Function App. For our deployment, the function build agent is used to install Python requirements and copy the package to the function App. There is a dedicated DevOps task for function deployments, which you can explore. For the moment we had a better experience installing the azure-functions-core-tools on the DevOps build agent (ubuntu) and publishing our function with it (Code 10, step 5).

Discussion
In this blog we present a pipeline architecture that supports Continuous AI on Azure with a minimal amount of moving parts. Other solutions we encountered add Kubernetes or Docker Instances for publishing the AzureML models for consumption by frontend facing functions. This is an option, but it might increase the engineering load on your team. We do think that adding Databricks could enrich our workflow with collaborative notebooks and more interactive model training, especially in the exploration phase of the project. The AzureML-MLFlow API allows you to register model from Databricks notebooks and hook into our workflow at that point. Later in the project with the model running in production for some time an AzureML pipeline could make more sense as a platform for regular model updating.
Full model training
Our focus is on model training for incremental updates with training times measured in hours or less. When we consider full model training measured in days, the pipeline architecture can be expanded to support non-blocking processing. One option is for the running of the AzureML pipeline to be done with Azure Datafactory, which is more suitable for long running orchestration of data intensive jobs. If the trained model is deemed viable a follow-up DevOps pipeline can be triggered to deploy it. A low-tech trigger option (with limited authentication options) is the http endpoint associated with each DevOps pipeline.
Use cases
AI is not the only use case for our approach, but it is a significant one. Related use cases are interactive reporting applications running on streamlit, which can contain representations of knowledge that have to be updated. Machine Learning models, interactive reports and facts from the datalake work in tandem to inform management or customer and lead to action. Thank you for reading.